
Abstract
- Represent different characters in terms of Bit String
- There are many different character encoding standards like ASCII, GBK (character encoding) and UTF-8 etc
Incompatible Encoding Standard
Characters encoded in one standard may be displayed differently in another standard.
We should always use the same character encoding standard, UTF-8 is recommended. And if we see characters that are not displayed correctly, we shouldn’t save the file, because saving will overwrite the file with placeholders for those wrongly displayed characters.
Important
Programming languages like Python use the number of code point of the string as the length of the string, not the number of characters. One example is 👍🏻 which is represented with two code points, you will get two instead of one as the length of the string.
System programming languages more likely to use Unicode Unaware String Function which counts the number of Byte used to store a string.
UTF-8

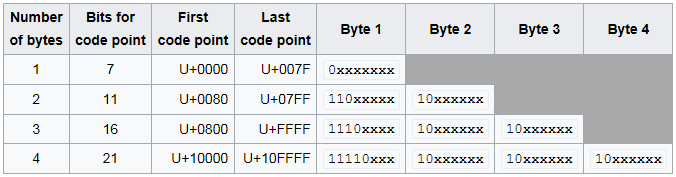
- UTF-8 allows variable-length encoding which means code point is variable-length, this brings a great amount of space saving to store different characters. As shown above, we use 1 Byte to store a, 4 bytes to store 😊, and 3 bytes to store 家. Without variable-length encoding, we need to use 4 bytes to store each character.
Unicode Unaware String Function
- Unicode Unaware String Function counts the numbers of Byte used by the string, and not the number of characters inside the string
- String in Go is encoded with UTF-8 and is treated as an Array of Byte. This explains why the index is off and
len(myString)returns , instead of
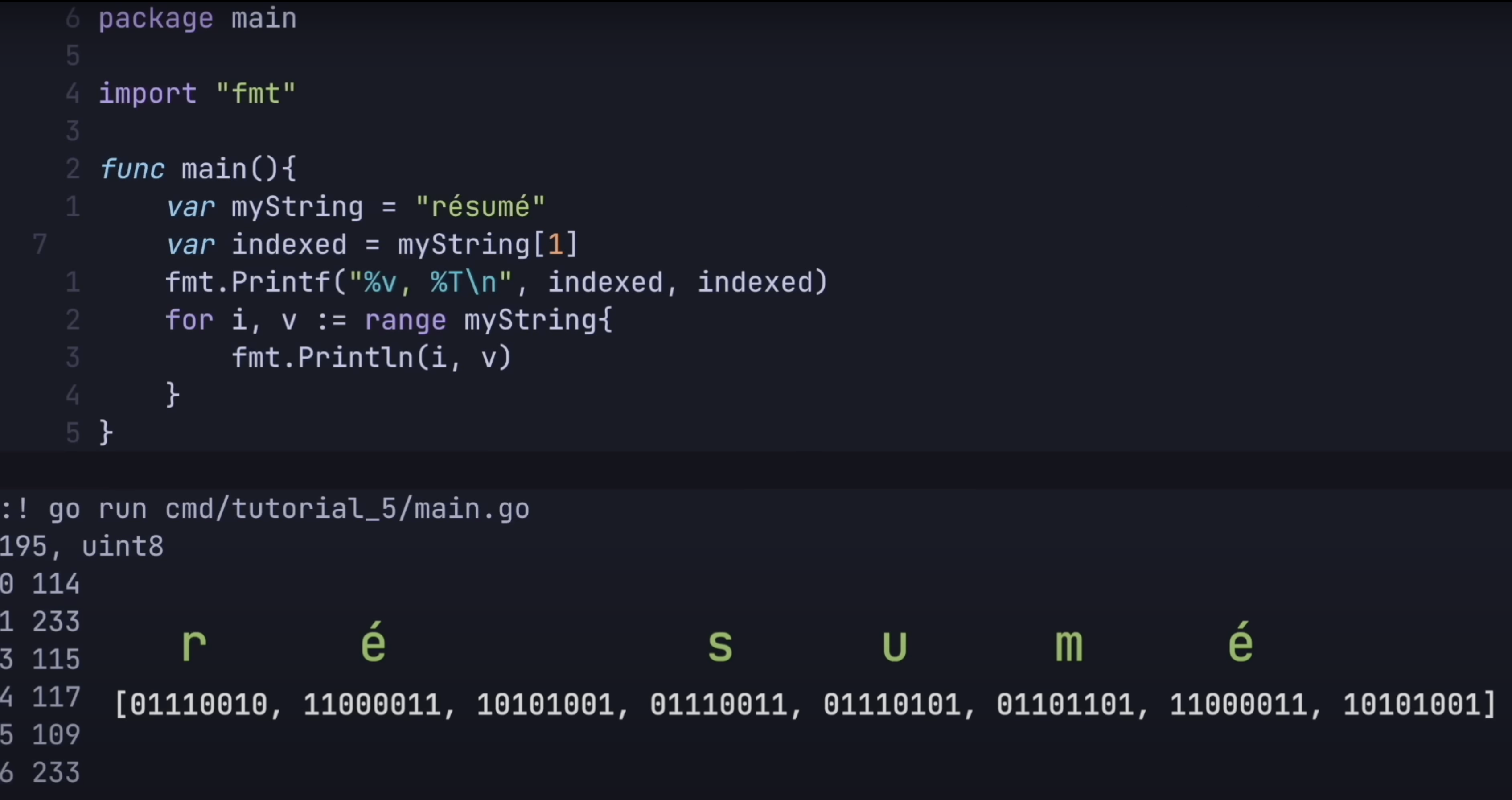
- This behaviour applies to other languages like C, you get when you run
printf("%d", strlen("😊家"));, instead of
Abstract away this weird behavior
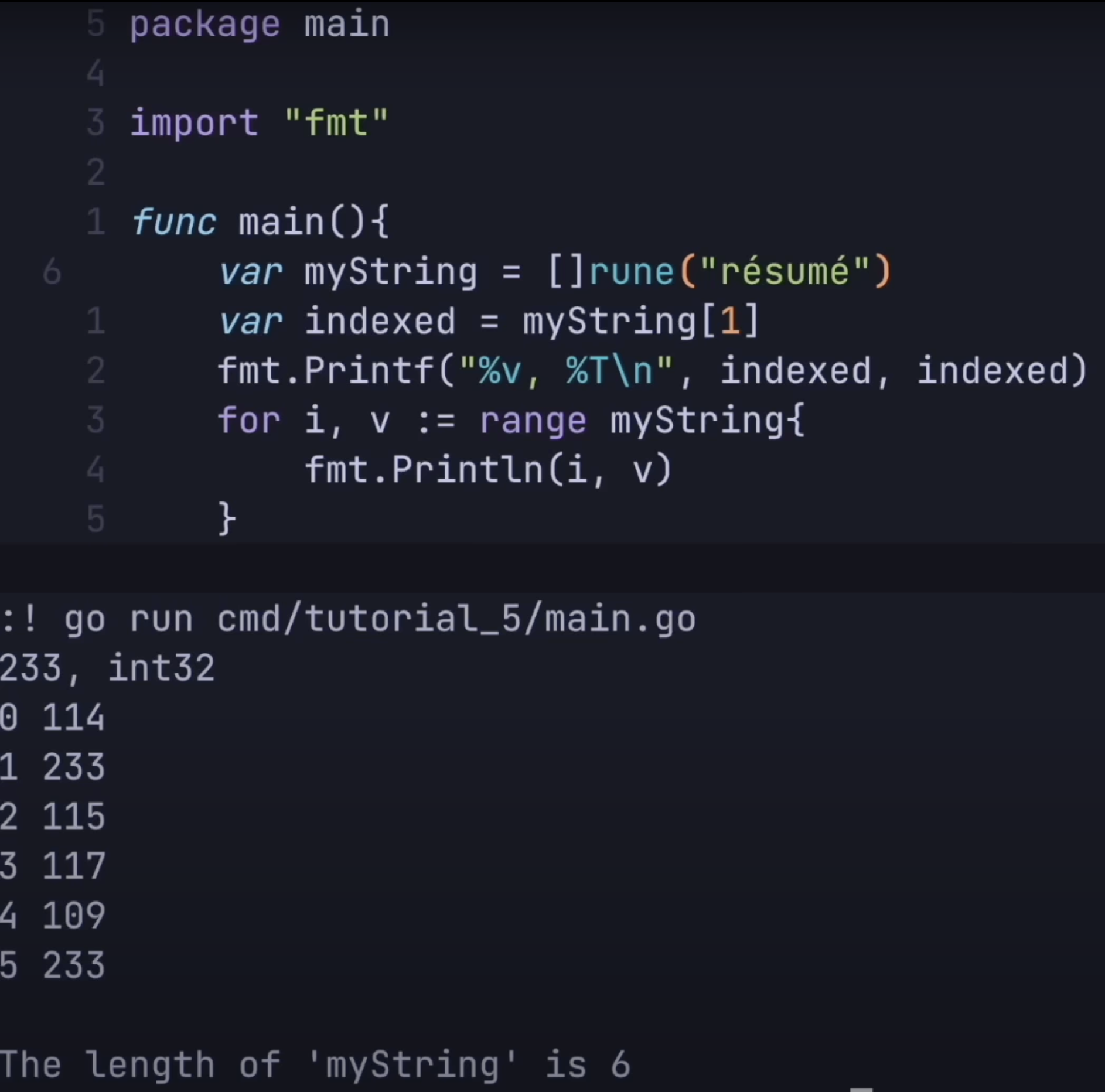
We can cast the string to an array of
runeto have an intuitive interface to the string in Go as shown below. Butruneas you can see below isint32, this approach comes with some space sacrifices.
{kind=link}