
Abstract
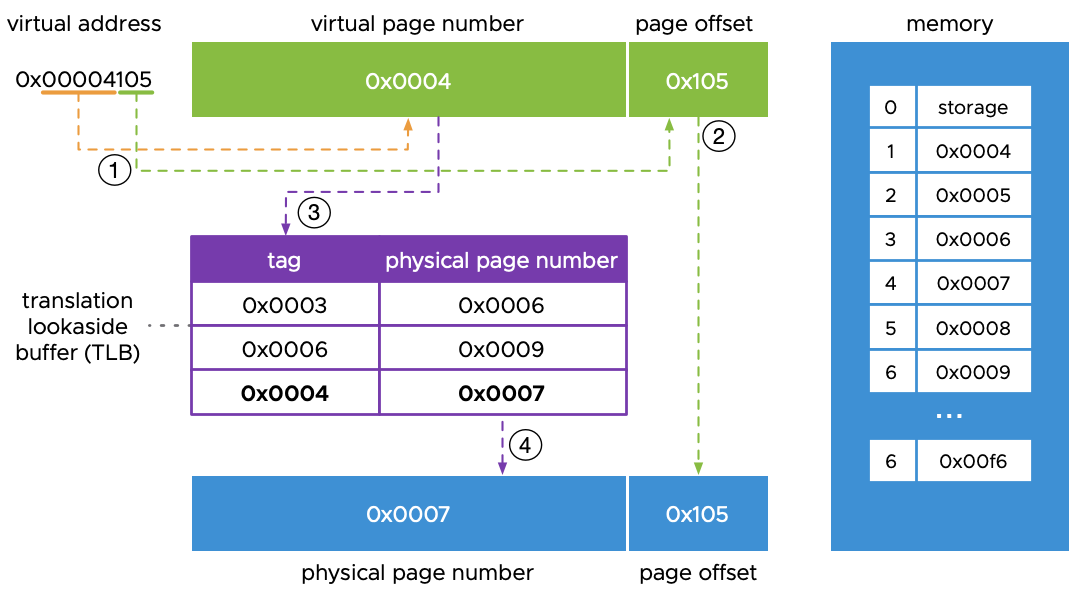
- Stands for Translation Lookaside Buffer
- Part of MMU that caches the PTE, fully associative cache, which is not Direct Mapped Cache (each cache line is mapped to a certain group of memory addresses)
Important
Super fast
- Address translation takes less than one clock cycle, and cache locality helps keep miss rates to just a few percent.
Super small
- Usually only contains or page table entries, while a page table usually contains 1 million entries.
Why do we need TLB?
To retrieve data from main memory, we first obtain the physical address from the page table, which also resides in main memory. We then use this physical address to access the data.
The TLB is a component of the CPU’s MMU. By caching recently used page table entries, the TLB eliminates the need for memory accesses, significantly improving the speed of obtaining physical addresses.

How to make TLB bigger?
Make pages bigger
- Making memory pages bigger increases the reach of the TLB. 64 PTEs (Page Table Entries) of 4kB pages only cover 256kB of data, while 32 PTEs of 2MB pages cover 64MB of data.
Add a second TLB
- This provides larger capacity but is slower. Most CPUs have a level 2 TLB that is about 8x larger than the level 1 TLB, but also twice as slow.
Use a dedicated hardware chip
- This is called “hardware page walk”. The hardware assumes the page table is in a special form in memory, allowing it to retrieve data on a TLB miss without involving the kernel, which is much faster.
iTLB
- TLB that caches page table entries for Instruction
dTLB
- TLB that caches page table entries for data
Data Retrieval Scenarios Involving a TLB
| No Page Fault | PTE in TLB | Performance |
|---|---|---|
| ❌ | ❌ | Even more horrible performance! It takes cycles to know the data is on swap space, and it takes about 80 million cycles to get the data from the swap space. |
| ❌ | ✅ | The performance is horrible. It takes one clock cycle to know the data is on swap space, but it takes about 80 million cycles to retrieve the data from the swap space. This is unlikely to happen because the TLB stores PTEs that have been recently accessed, and page faults typically occur for memory pages that are least recently used. |
| ✅ | ❌ | Poor performance, it takes cycles to load the PTE from main memory. The data is then retrieved from either main memory or the CPU cache. |
| ✅ | ✅ | Great performance, taking less than one clock cycle for address translation. The data is then retrieved from the main memory or CPU cache. |
TLB Lifecycle: From Initialisation to Eviction
TLB Initialisation
- The TLB is empty at this stage, and all virtual-to-physical address translations will result in TLB Miss initially.
TLB Hit
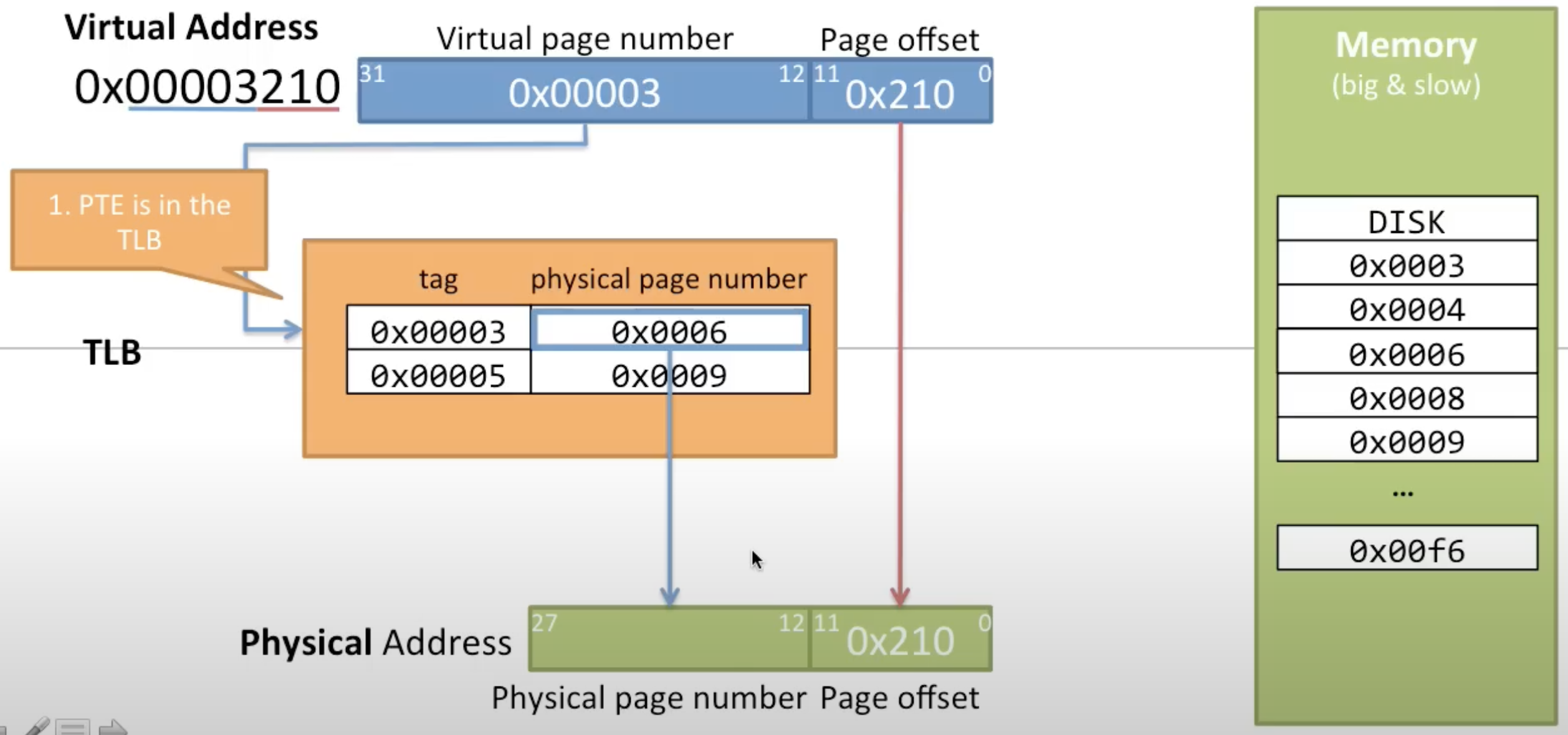
- This occurs when the CPU requests a virtual address translation, and the corresponding PTE is found within the TLB
- It is the fastest type of address translation since it doesn’t require accessing the page table in main memory
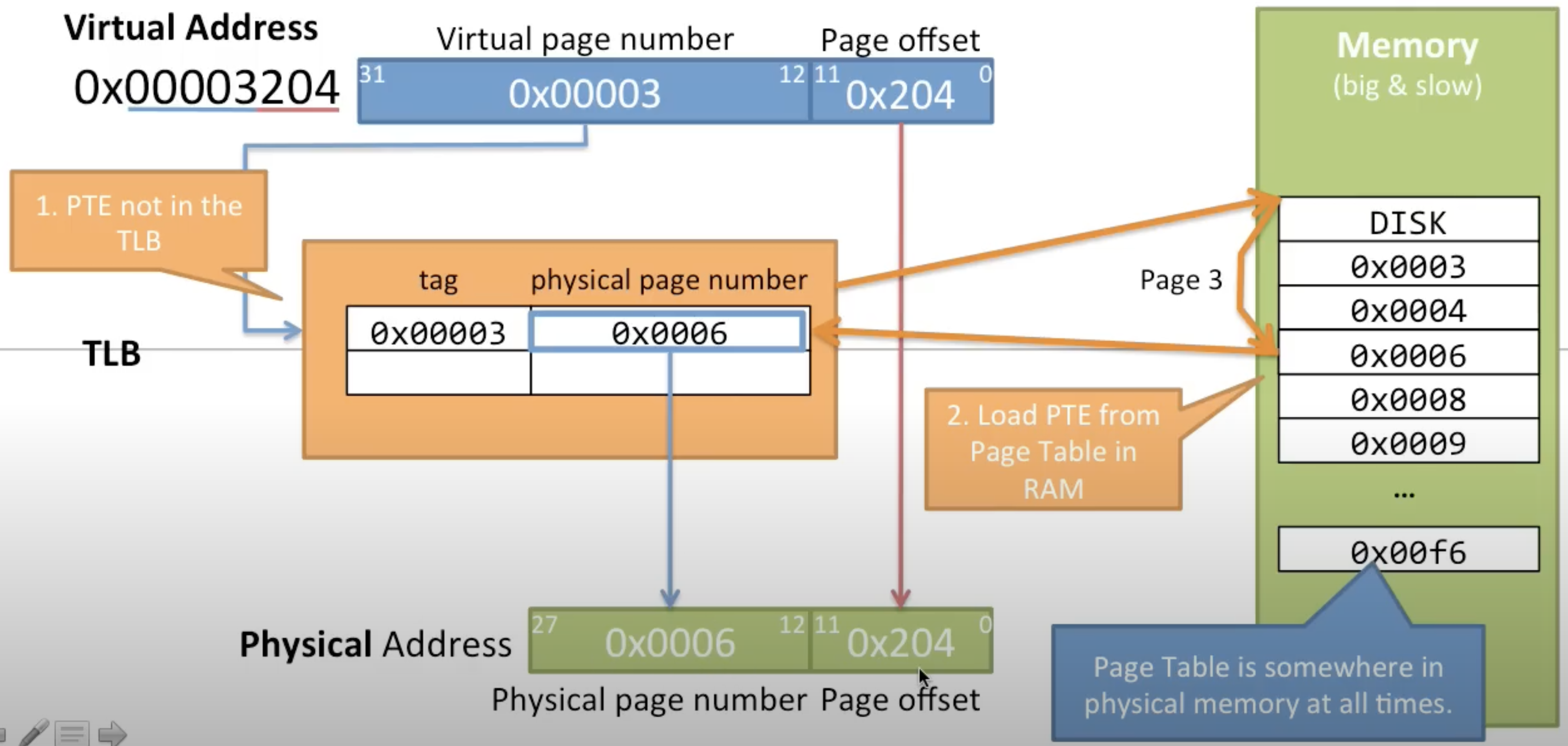
TLB Miss
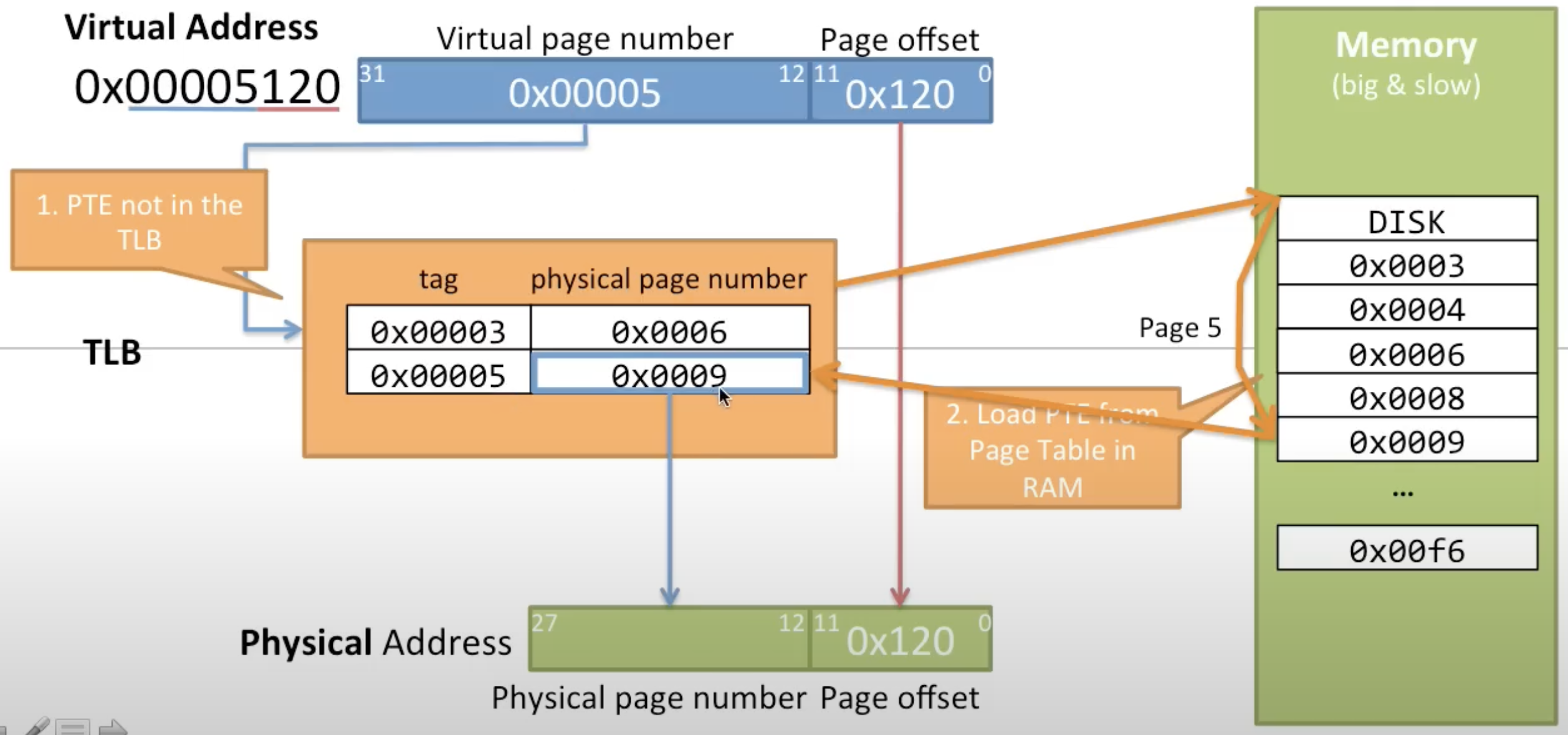
- This happens when the requested virtual address translation does not have a corresponding PTE in the TLB
- The CPU needs to access the page table in main memory to find the correct physical address
- This is slower than a TLB Hit and can cause a performance penalty
TLB Eviction
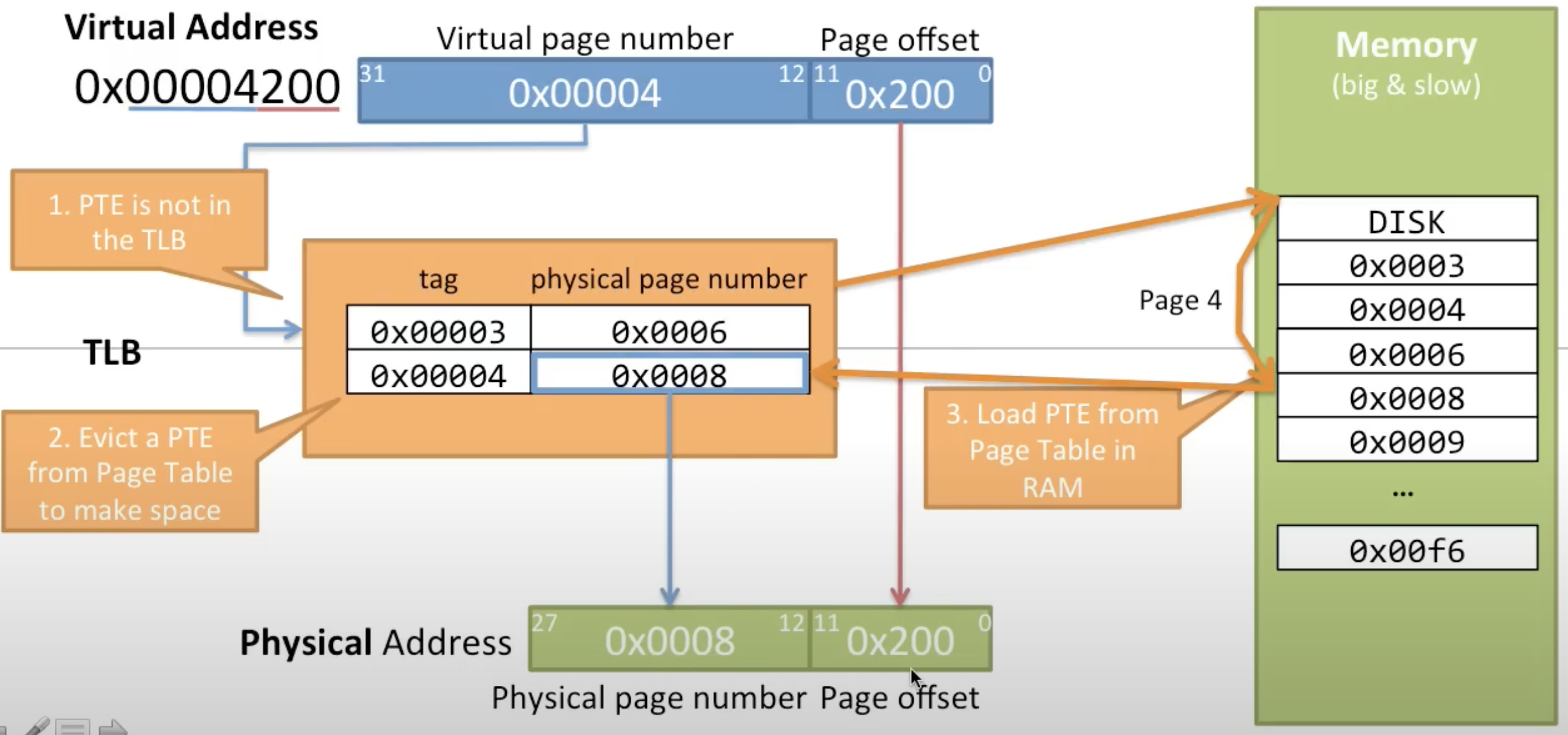
- Due to the limited size of the TLB, it cannot hold all possible PTEs
- When the TLB is full and TLB Miss occurs, a new PTE needs to replace (or evict) an existing one to make room. The replacement policy (e.g., Least Recently Used) determines which entry gets evicted