
Abstract
- Also known as Dynamic Optimisation
- A technique utilised to divide a given problems into smaller problems, optimal answers to those smaller problems generate the optimal answer to the given problem, and the efficiency of the process is improved by making use of Memoization to remember the answers to those smaller problems, so we avoid duplicated computation
Dynamic
I wanted to get across the idea that this was dynamic, this was multistage, this was time-varying. - Bellman
So Dynamic programming is also known as Multistage Optimisation. The multstage here refers to the stages of solving subproblems which deliver the final optimal answer to a given problem.
- There are two main approaches to DP algorithms - Top-down DP Approach and Bottom-up DP Approach
- There are two main use-cases
- Combinatorial Optimisation (finding an optimal solution)
- Counting the total number of solutions for a given problem
DP Debugging
Print out DP Table to check any errors.
Question Bank
Top-down DP Approach
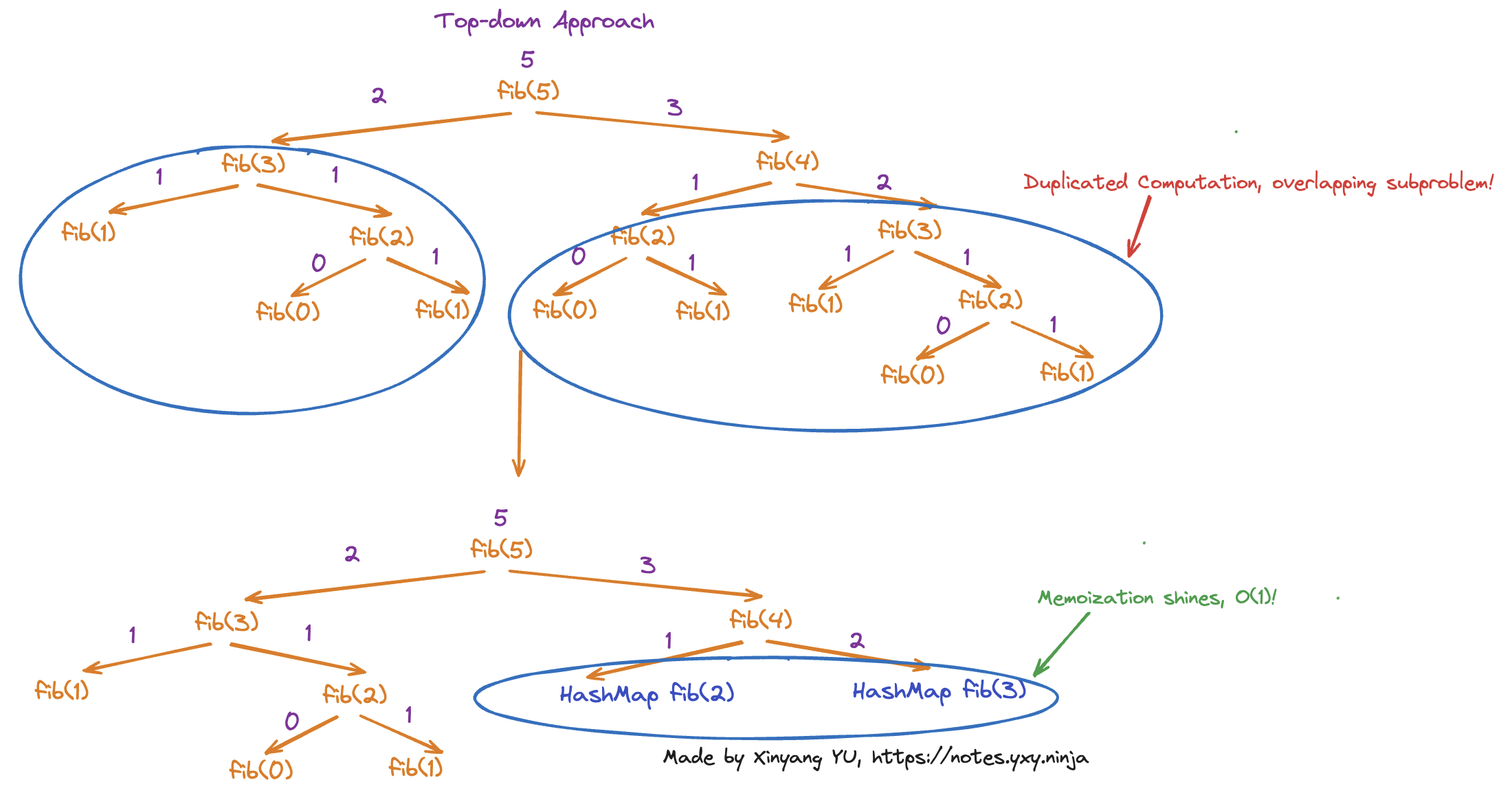
- Start with the large, complex problem, and understand how to break it down into smaller subproblems, perform Memoization by recording down the answer of subproblems to avoid duplicated computation on overlapping subproblems. Above shows how can we make use of top-down approach to find Fibonacci sequence in
Attention
The space complexity of Top-down approach is , we need to record down the answer for all the subproblems.
When we break down the larger problem into smaller subproblems, some subproblems may already be solved but some aren’t. The size of subproblems can vary, so we have to record down the answer to each solved subproblems, so we can solve that subproblem in if we see that subproblem again.
Divide and Conquer
- Top-down DP Approach without Memoization, because overlapping subproblems aren’t a requirement for the Divide and Conquer approach
- Make use of Recursion to divide a given problem into smaller subproblems until its smallest form whose answer is known. We combine the answers of smaller subproblems into the answer of a bigger subproblem when the function calls on the smaller subproblems return
- For example, Merge Sort uses Divide and conquer
Bottom-up DP Approach
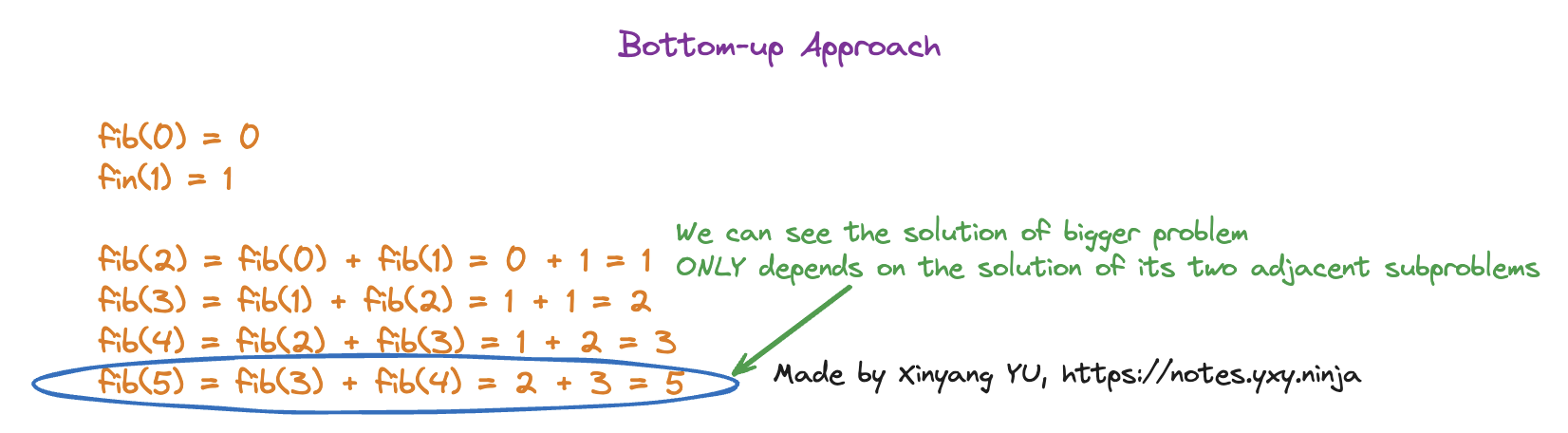
- Start with the smallest possible subproblems, figures out the solution to them, and then slowly builds itself up to solve the larger, more complicated subproblem
Space efficient
The space complexity of Bottom-up approach is , we just need to save the solutions of adjacent subproblems to obtain the answer to the bigger problem.
It is like finding the solution to , we already know is , then the answer to is simply which is . You see we don’t need to remember what is the answer to or , because the answer of depends directly on , nothing else.
DP Problem Properties
Overlapping Subproblems (重复子问题)
- Occur when a problem can be broken down into smaller subproblems that are exactly the same
Tip
Overlapping subproblems can be handled efficiently with Memoization.
Optimal Substructure (最优子结构)
- When a problem has optimal substructure, we can use the optimal solutions of the subproblems to construct the optional solution of the given problem
Knapsack Problem
The solution can be found by building on the optimal solutions to the knapsack problem with smaller weights and values.
Statelessness (无后效性)
- Solutions to smaller problems are deterministic. For example, the answer of depends directly on , nothing else
- We can expand the definition of DP Table to keep track the state of more complex problems, aka building up from the optimal solution of smaller subproblems. However, problems like Travelling salesman problem - Wikipedia is too complex to have the solutions of its subproblems modelled into a dp table. Thus, can’t be solved with the help of Dynamic Programming
Dependency order of subproblems

- In order to be solved with dynamic programming, the dependency order of subproblems of a given problem MUST follow topological sort order, as shown above
- Think about the answer of depends directly on , nothing else. If depends on , there is no way for us to build up the solution from smaller subproblems!
State Transition Equation (状态转移方程)
-
The Recurrence Function we need to perform to transit from one state(bigger subproblems) to a smaller state(smaller subproblems), comes with a base case for the smallest form of the problem
-
Fibonacci sequence
Important
Theoretically, if a problem fulfils the Overlapping Subproblems (重复子问题) and Optimal Substructure (最优子结构) properties, we are able to come up with the state transition equation.
0-1 knapsack problem
In 0-1 knapsack problem, the scope is basically the number of the items we can select. The less the items available to be selected the smaller the scope.
The smallest scope is item, in this case, the maximum value we can obtain is always regardless the size of the knapsack bag.
Then we expand the scope from item to item. What is the mathematical operation we need to perform to obtain the new state of the new scope?
The answer is to loop through the knapsack size from to the maximum size. At each size, if the weight of the new item exceeds the knapsack size, we get a bigger knapsack size until we get one that is big enough for the new item. The new state in this case is just the state of the previous smaller scope.
When the knapsack size is big enough, there are 2 choices for us, it is either we put the new item into the bag or we don’t. So how? Remember we want to maximise the value we can have inside the knapsack bag, so we should always make the decision that increments the value in the new state.
Lets abstract the problem:
- Let be the current knapsack bag size
- Let be the previous state with , basically the best value we can have with
- Let be the weight of the new item
- Let be the value of new item
So now we want to perform state transition which is to obtain the best value with bigger scope at . How should we do that?
The answer is simple, we only put the new item into the knapsack bag if it can generate a bigger value at .
We know the previous state is the best state at that smaller scope. So we can build on top of it! If I put in the new item, the best value it can generate is basically the best value at at the previous state(let this best value be ) + . If we don’t put the new item, the best value is basically .
Thus, we obtain our State Transition Equation. The new state at is
Math.max(q + v, p). We put the new item into the bag if , else we don’t.