
Abstract
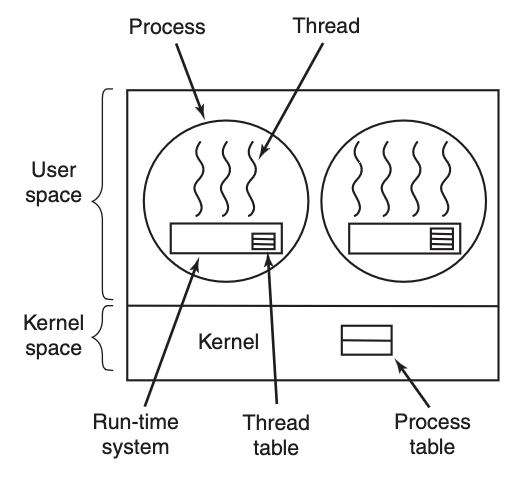
- Thread are managed entirely in User Space, running on top of a Runtime System. A user thread library is used to implement the threads
- Each process maintains its own private thread table, in contrast to the thread table managed by the kernel for kernel threads
{kind=link}
Important
With a pure user-space threading model (many-to-one), the kernel perceives a process with multiple user threads as a single kernel thread.
When a page fault occurs, it is not possible to schedule another thread within the same process to run. This limitation can be addressed by adopting a kernel-supported threading model, such as a one-to-one kernel thread mapping or a many-to-many hybrid threading model
Key advantages
Portability: Threads can be implemented on a kernel that does not natively support threads.
Performance: Thread switching is significantly faster than kernel-based switching, with no need for Trap Interrupt (陷入) or Context Switch, and the CPU Cache does not need to be flushed.
Customisation: Each process can implement its own customised process scheduling algorithms without altering the kernel code.
Scalability: Unlike Kernel Thread, which require additional table space and Stack Segment in the kernel, user threads avoid these limitations, supporting better scalability for large numbers of threads.
Risk of thread hogging
If a user thread starts running, no other user thread in the same process will execute unless the first thread voluntarily relinquishes the CPU. Within a single process, there are no Interrupts (中断), making it impossible to schedule threads in a round-robin manner.
Implementing Interrupts (中断) in the Runtime System is resource-intensive.
Runtime System
- Contains a Thread Scheduler in User Space for managing User Thread
Thread blocking
The thread calls the runtime system to check if it needs to be put into a blocked state. If so, the runtime system stores the thread’s registers (i.e., its state) in the thread table and searches the table for a thread that is ready to run.
Scheduler Activations
- Instead of relying on the Kernel for every thread management decision, the Runtime System is responsible for scheduling Thread
- This approach mitigates inefficiencies caused by kernel involvement in thread management