Abstract
+-----------------------------------------------------------+
| 32-bit Address |
+-----------------------+------------+----------+-----------+
| Block | Offset |
| Number | |
| (29 bits) | (3 bits) |
+-----------------------+------------+----------+-----------+
| Cache | Set | Word | Byte |
| Tag | Index | Offset | Offset |
| (28 bits) | (1 bits) | (1 bits) | (2 bits) |
+-----------------------+------------+----------+-----------+
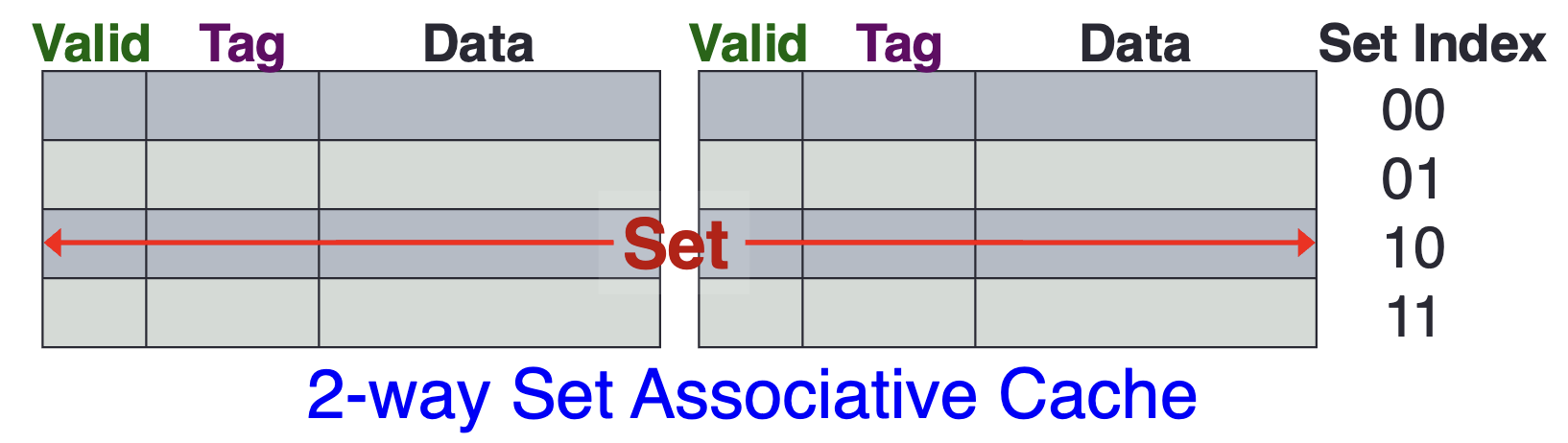
- One way to design a CPU cache is to have it consist of a number of sets, each containing cache lines. Within a set, a memory block can be placed in any of the cache lines.
- In the above example, we have a 2-way set associative cache. The CPU Cache has sets, each containing cache lines. Each contains words, and each word is bytes
What is the benefit?
Set associative caches reduce the likelihood of conflict misses compared to direct-mapped caches. In a direct-mapped cache, if two frequently accessed memory locations map to the same cache index, they will constantly evict each other, causing repeated conflict misses. A set associative cache provides multiple cache lines within each set, allowing these memory locations to coexist in the cache simultaneously, minimising conflict misses and improving performance.
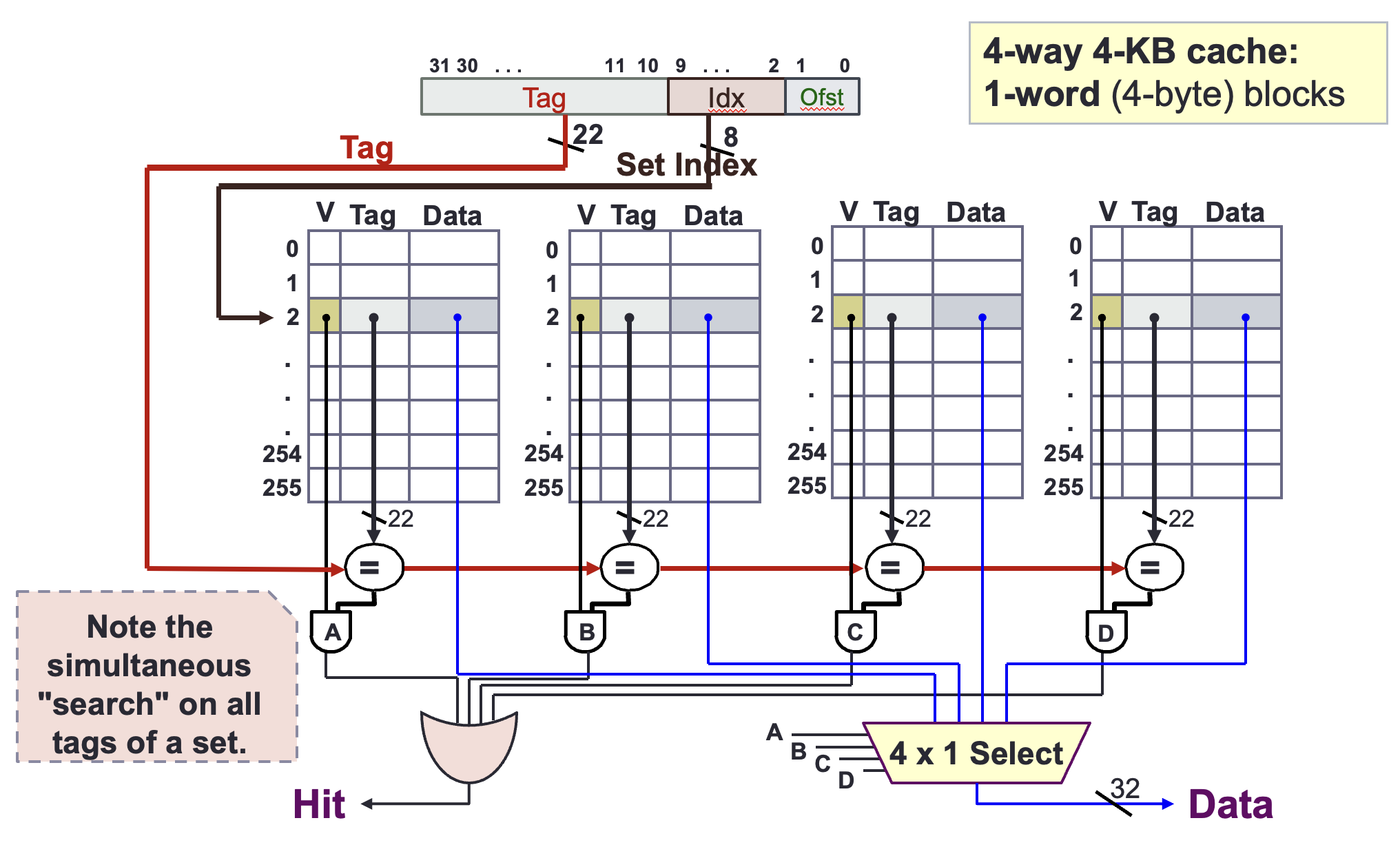
How is data read?
- We first use the set index to locate the set
- We simultaneously “search” on all valid bit and tags of the set to check if one of the cache line contains data. If it does, and the tag matches the given address, we can select the word needed using with a help of a Multiplexer
- Otherwise, there is a cache miss.