
Abstract
- 2 Main Components - ALU, Control Unit
- Fire the necessary components based on the given Instruction
- Start in Kernel Mode. Before executing a program, the kernel initiates the switch to User Mode
Success
Optimised for computation that requires sequential execution(one Instruction can only execute when another Instruction finishes), Pipeline Branching and logic.
Understand the Intel/AMD CPU naming
This video explains the naming mechanism of Intel/AMD CPU pretty well.
Chip Binning
Chip manufacturing isn’t perfect. A CPU manufactured with CPU cores may only have 8 that are working. Chip Binning is the process of selling chips with detects as a lower-tier CPUs at a lower cost by disabling the areas with defects. This massively improves the yield of a wafer because it means that more dies can be utilised and sold.
The M4 chip comes with iPad Pro 2024, the more expensive version includes one additional performance CPU core and 8GB more DRAM.
CPU Core
- One single unit of CPU that executes Instruction independently from other CPU cores
32-bit CPU
- Register Width that are 32 Bit each
- The size of Memory Address is limited to 4GB. Because 32bits Register can only hold 4GB different unique memory address,
- The Word size is usually 4 Byte
64-bit CPU
- Register Width that are 64 Bit each
- Doesn’t have the 4GB Main Memory limitation in 32-bit CPU
- The Word size is usually 8 Byte
CPU Scratch Area
- A small amount of high-speed memory that is used to store temporary data in the CPU. Register and CPU Cache are considered as CPU Scratch Area
Hyperthreading
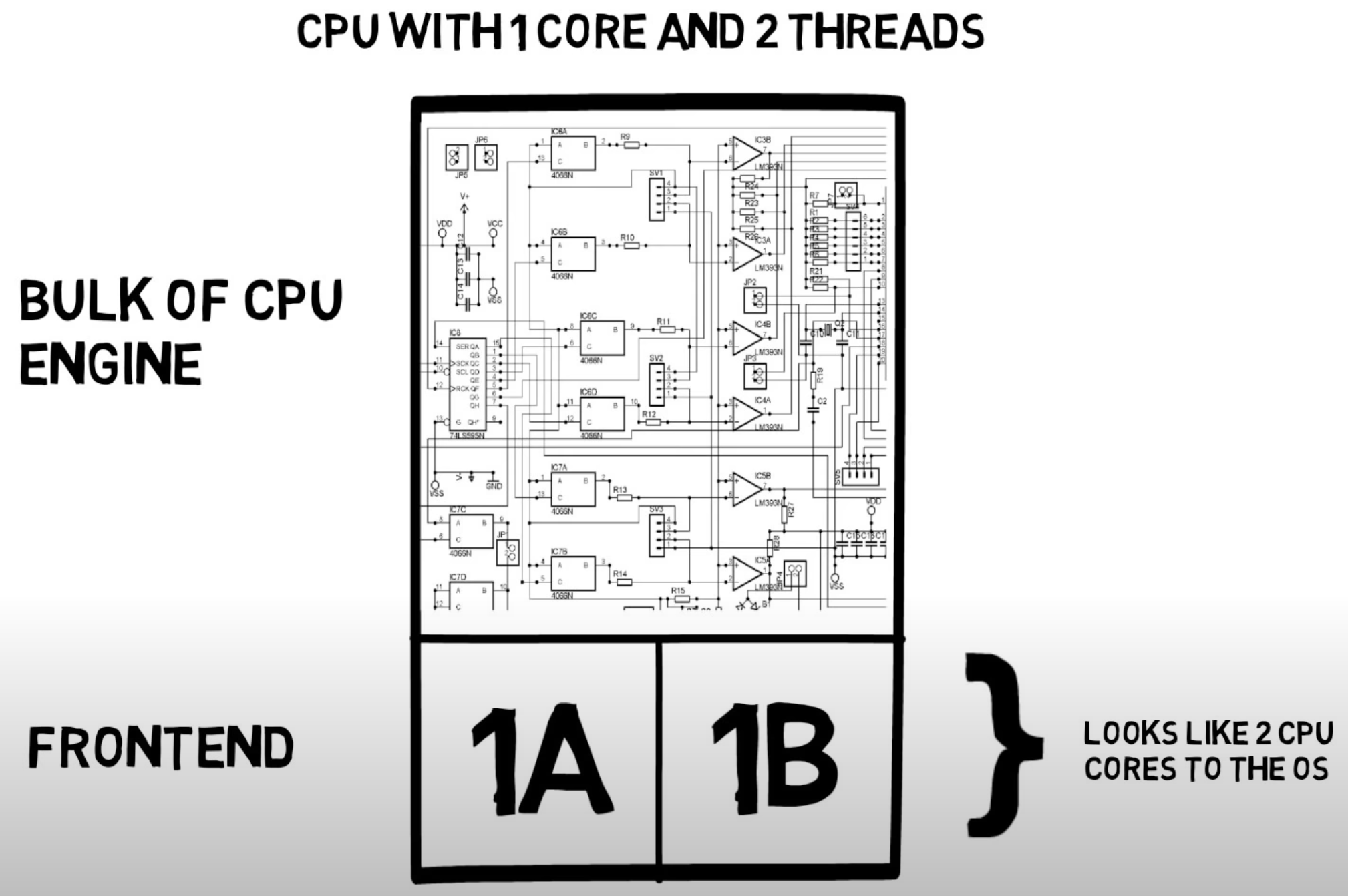
- Hyperthreading technology enables a single CPU to handle multiple Thread simultaneously. Thus, achieving Parallelism (并行)
- This is achieved by duplicating the Register File like Program Counter. Fetch and Decode are also duplicated to allow for simultaneous processing of Instruction from multiple Thread. The rest like ALU is shared
Important
The performance gain from Hyperthreading is minimal when one set of the fetch and decode is smooth and able to keep the ALU busy.
However, if one set of the fetch and decode is not smooth in the cases like Pipeline Flush, the another set of fetch and decode can keep the ALU busy, thus improving performance.
The rule of thumb is that every CPU Core that supports hyperthreading has roughly an additional CPU core performance.